Local Stories
Girls Who Code: Local chapter highlight
Discover the Girls Who Code chapters in Ting towns.
.jpg)

Discover the Girls Who Code chapters in Ting towns.

Is Ting Internet a better choice than Cox? Dive into our comprehensive analysis covering speed, reliability, value, and customer support, and make...
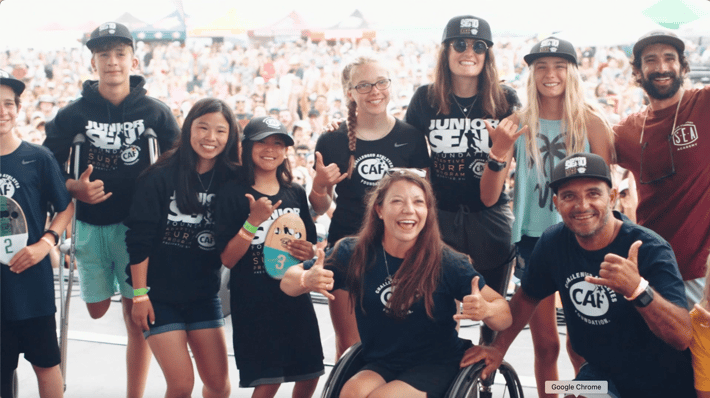
It’s all about surfing, music and supporting the community with Ting Internet at the Switchfoot Bro-Am Beach Fest on June 15, 2024.
Not all high-speed connections are created equal. But what exactly qualifies as "fast" internet? Let's find out.

Did you know fast upload speeds are crucial for activities like video calling, cloud storage, and gaming? Read our blog on why upload speeds matter.

This month's Ting Internet Employee Spotlight shines on Heather Smith, a product manager who has been with the company for two years.

Ting has began lighting our first neighborhood in Greenwood Village, CO! Discover how we're bringing Greenwood Village into the future with 2 gigabit...
Order Ting Internet before April 2, 2024 using promo code SLAMDUNK and get $200 in account credit. You'll also be entered for a chance to win a...

Mediocre internet, confusing prices and terrible customer service? Not with Ting Internet!

This Black History Month, we’re excited to share a round-up of some of our favorite Black-owned and -operated businesses across our Ting communities.

Discover if fiber internet’s lightning-fast speeds and reliability justify the cost—plus what sets Ting apart from other fiber providers.

Celebrate World Computer Literacy Day by enhancing your tech skills and helping others do the same.